Разработка RAG-систем и умных баз знаний
Ваши сотрудники часами ищут нужную информацию в тысячах документов. Клиенты задают одни и те же вопросы в поддержку. Юристы тратят 30 минут на поиск прецедента в базе договоров. Знакомо?
RAG-система (Retrieval-Augmented Generation) — это умная база знаний на искусственном интеллекте, которая мгновенно находит ответы в ваших документах и формулирует их на естественном языке. За 16 лет в веб-разработке мы видели, как компании тонут в информационном хаосе — RAG решает эту проблему технологично.
Что такое RAG-система
RAG (Retrieval-Augmented Generation) — технология, которая комбинирует семантический поиск по вашим документам с генерацией естественных ответов через языковые модели.
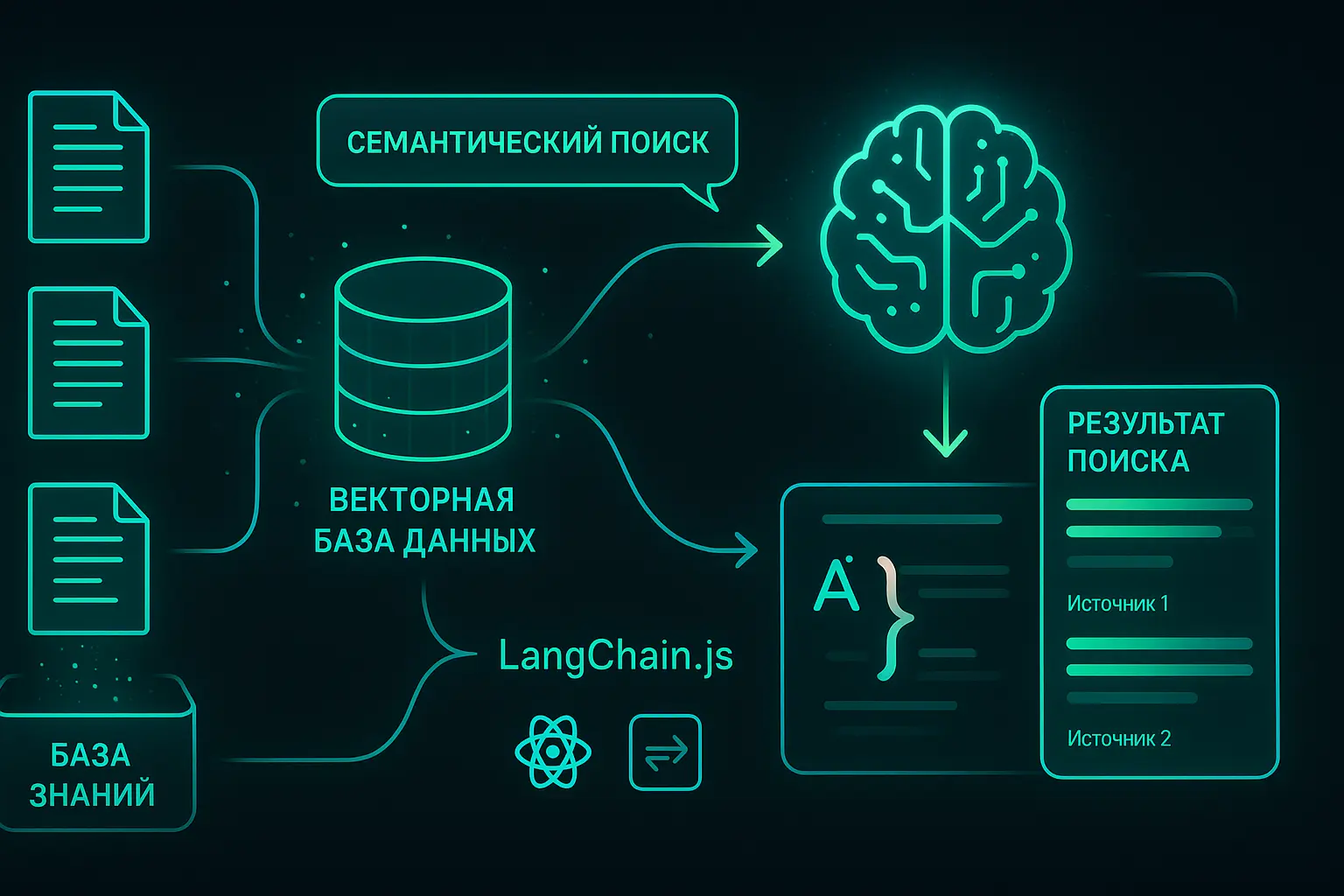
Как работает RAG (простыми словами):
1. Загружаете документацию PDF, Word, Markdown, Confluence, Notion, внутренние wiki — любые форматы.
2. Система индексирует контент Документы разбиваются на фрагменты и преобразуются в числовые векторы (embeddings). Векторы попадают в специализированную базу данных.
3. Пользователь задаёт вопрос "Как настроить интеграцию с API?" — формулировка любая, не обязательно точная.
4. Семантический поиск Система ищет похожие по смыслу фрагменты, а не по ключевым словам. Понимает контекст и намерение.
5. Генерация ответа Языковая модель читает найденные фрагменты и формулирует ответ на естественном языке с указанием источников.
RAG vs Обычный чат-бот vs Поиск по сайту
| Критерий | RAG-система | Чат-бот на правилах | Поиск по сайту |
|---|---|---|---|
| Источник знаний | Ваши документы | Заранее прописанные сценарии | Индекс страниц |
| Актуальность | Всегда актуальные данные | Нужно обновлять вручную | Зависит от переиндексации |
| Точность | 90-95% (ответы только из документов) | 70-85% | 60-75% |
| Понимание контекста | Да, семантика | Нет, только ключевые слова | Частично |
| Источники | Ссылки на документы | Нет | Список страниц |
| Обучение | Загрузка новых документов | Переписывать сценарии | Ждать переиндексацию |
| Ответы на нестандартные вопросы | Да | Нет | Нет |
Как мы создаём RAG-системы
1. Анализ документации и источников
Изучаем вашу базу знаний: форматы документов, объём, структура, существующие категории. Определяем, откуда брать данные — локальные файлы, Confluence, Google Drive, внутренние системы.
2. Архитектура и выбор стека
Подбираем оптимальную комбинацию: языковая модель (GPT-4, Claude, открытые модели), векторная база данных (Pinecone, Weaviate, ChromaDB), фреймворк (LangChain, LlamaIndex), способ развёртывания (облако или on-premise).
3. Векторизация и индексация
Разбиваем документы на оптимальные фрагменты (chunking), генерируем embeddings, загружаем в векторную БД. Настраиваем метаданные для фильтрации: категории, даты, авторы, теги.
4. Настройка поиска и генерации
Калибруем семантический поиск: количество релевантных фрагментов, порог схожести, гибридный поиск (semantic + keyword). Настраиваем промпты для языковой модели — как формулировать ответы, когда говорить "не знаю".
5. Интерфейсы и интеграции
Создаём веб-интерфейс (чат), админ-панель для управления базой знаний, API для интеграции с сайтом, CRM, Telegram, Slack. Настраиваем уведомления и логирование.
6. Аналитика и улучшение
Собираем статистику: какие вопросы задают, где система не нашла ответа, какие документы популярны. На основе данных дополняем базу знаний, улучшаем промпты, настраиваем поиск.
Семантический поиск
Ищет по смыслу, а не по ключевым словам. Понимает синонимы и контекст.
Любые источники
PDF, Word, Confluence, Notion, Google Drive, внутренние wiki, веб-страницы.
Мгновенные ответы
Поиск и генерация ответа за 2-5 секунд вместо 30 минут ручного поиска.
Ссылки на источники
Каждый ответ содержит ссылки на документы, откуда взята информация.
Автообновление
Загрузили новый документ — система сразу обучилась. Никаких переобучений.
Безопасность
Контроль доступа по ролям. On-premise развёртывание для конфиденциальных данных.
Цены на разработку RAG-системы
Стоимость зависит от объёма данных, сложности интеграций и требований к инфраструктуре. Указанные цены — базовые, финальная стоимость рассчитывается индивидуально после анализа задачи.
Базовый
- До 1000 документов
- Базовая RAG-архитектура
- Веб-интерфейс (чат)
- Семантический поиск
- Ответы с источниками
- Облачная векторная БД
- Срок: от 25 дней
Стандарт
- До 10 000+ документов
- Гибридный поиск (semantic + keyword)
- Аналитика и дашборд
- Интеграции (Telegram, Slack, API)
- Админ-панель
- Фильтры и метаданные
- Срок: от 21 дня
Enterprise
- Неограниченный объём
- Кастомные embeddings
- Мультиязычность
- Сложная логика (multi-step)
- On-premise развёртывание
- Интеграция с CRM/ERP
- Срок: от 30 дней
Что НЕ входит в стоимость:
- Подготовка и структурирование документов (если ваша база хаотична — поможем за доплату)
- API-ключи языковых моделей и векторных БД (~5 000-50 000₽/месяц в зависимости от нагрузки)
- Хостинг для on-premise решения (если выбрали не облако)
- Техподдержка после запуска (есть опция от 30 000₽/мес)
Как мы работаем
Анализ документации
Изучаем вашу базу знаний: форматы, объём, структура. Определяем источники данных, болевые точки пользователей.
Проектирование архитектуры
Выбираем стек технологий под вашу задачу: языковая модель, векторная БД, фреймворк. Проектируем схему интеграций.
Разработка и индексация
Векторизуем документы, настраиваем поиск и генерацию ответов. Создаём веб-интерфейс и API.
Интеграции и тестирование
Подключаем CRM, мессенджеры, внутренние системы. Тестируем точность ответов на реальных вопросах.
Запуск и обучение
Разворачиваем систему, обучаем ваших сотрудников работе с админ-панелью. Передаём документацию.
Технологии и стек RAG-разработки
Разработка RAG-систем требует продвинутого технологического стека с языковыми моделями, векторными базами данных и фреймворками для AI:
AI/ML
Векторные БД
Backend
Интеграции
Почему RAG-система от Без Рутин эффективнее
Фокус на точности, а не на хайпе
Не гонимся за новейшими моделями ради маркетинга. Выбираем стек под вашу задачу: иногда GPT-4 избыточен, достаточно GPT-3.5 с правильными промптами. Иногда нужен Claude с контекстом 200K токенов. Проектируем на результат.
Гибридный поиск: semantics + keywords
Чистый семантический поиск иногда промахивается на точных запросах (например, номера статей законов, технические термины). Комбинируем semantic search с классическим keyword search — получаем лучшее из обоих миров.
Аналитика пробелов в базе знаний
Собираем статистику: какие вопросы задают, где система не нашла ответа. Показываем, какие темы нужно дополнить в документации. RAG не только отвечает — помогает улучшать базу знаний.
On-premise для конфиденциальных данных
Медицинские карты, финансовые документы, коммерческая тайна — не все данные можно отправлять в облако. Разворачиваем RAG на ваших серверах с открытыми моделями (Llama, Mistral) — данные не покидают инфраструктуру.
Часто задаваемые вопросы
Заказать разработку RAG-системы
Заполните форму ниже — мы свяжемся в течение 2 часов (в рабочее время), проанализируем вашу базу знаний и предложим оптимальное решение.
Остались вопросы?
Оставьте заявку — мы свяжемся с вами в течение 2 часов
Оставьте заявку
Предпочитаете мессенджер?
